软件缺陷晚修复的成本为什么是早期的100倍?
作者:上海惠艾技术总监/DevOps技术顾问 谈宏明
前言
在《质量内建的最大价值是降本增效》里,我们分析的结论是,上海惠艾质量内建实践能大幅减少返工成本,从而直接支持“降本增效”。中间提到缺陷应尽早修复,后期修复的返工成本是早期的100倍(Boehm博士:注1), 有些同学反馈询问,同一个缺陷修复,为什么尽早修复和后期修复的差距这么大?多出来的成本具体有哪些?

Boehm博士的100倍并不是最大数字,还有《Applied Software Measurement: Global Analysis of Productivity and Quality 》(注2)中的更大的640倍,如下图:
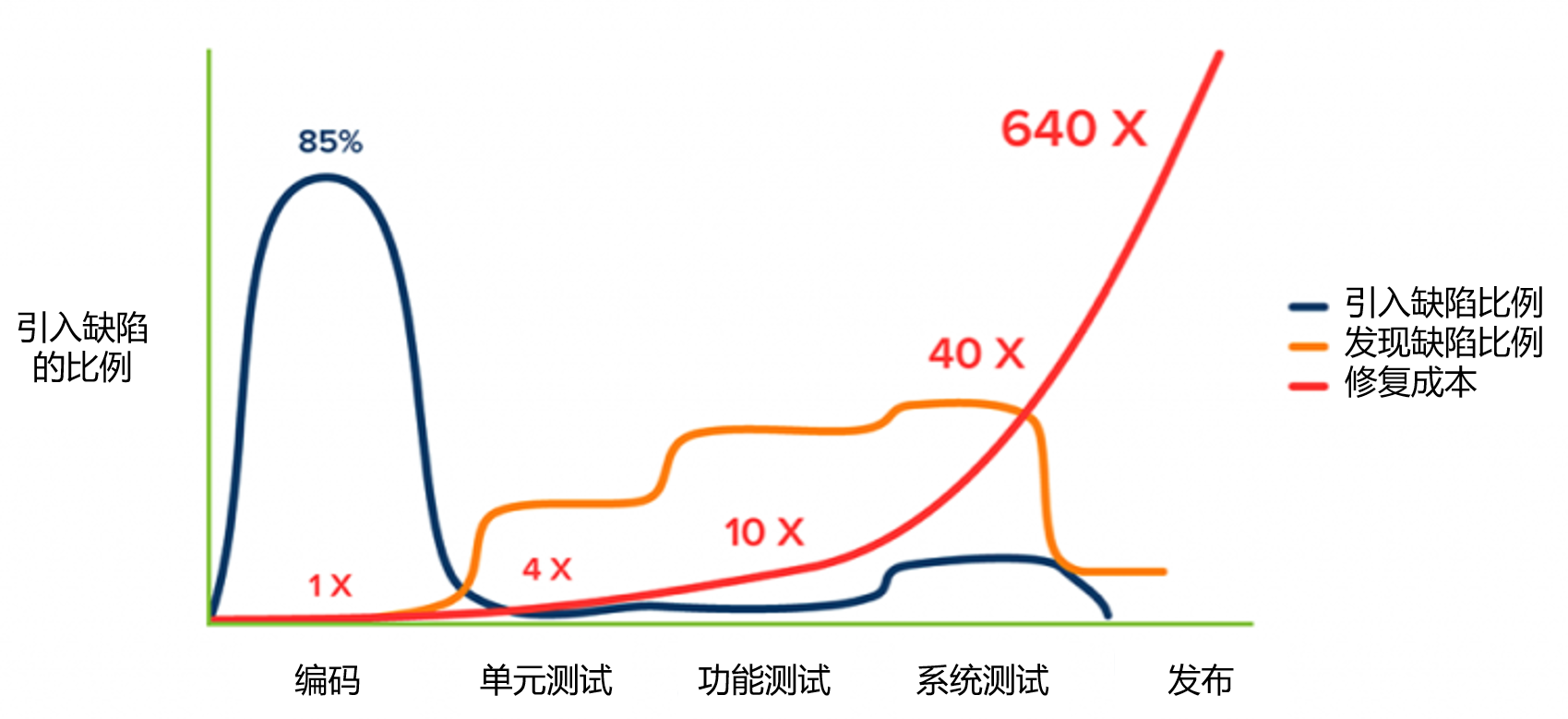
上海惠艾在帮助多家大型金融组织导入质量内建实践时,有用户总结了他们的返工过程的工作项和流程,以及成本构成,我们借此能更好的理解为什么返工成本如此高昂,缺陷 / 故障修复过程也不是“把螺丝拧拧紧”那种简单工序。
1、后期修复缺陷/故障的返工分析
当SIT缺陷 / 生产故障从天而降,开发人员需要放下手头工作(正在开发当前版本的代码),理解(上个版本的)缺陷,对缺陷发生位置进行详细定位(缺陷定位),识别故障点(错误日志分析),想办法重现问题(重现问题需要环境、数据都要近一致),然后核对初始的需求,以及设计,再从代码库检出对应版本的代码,通过调试来确定问题发生的具体原因,此时着手设计修复方案,对修复方案做快速影响分析,是否有其他衍生影响,确认方案无误后,动手修复,并验证修复结果,确认修复后,(如果是故障)申请投产版本的代码分支解锁,提交代码,申请提测。如下图所示:
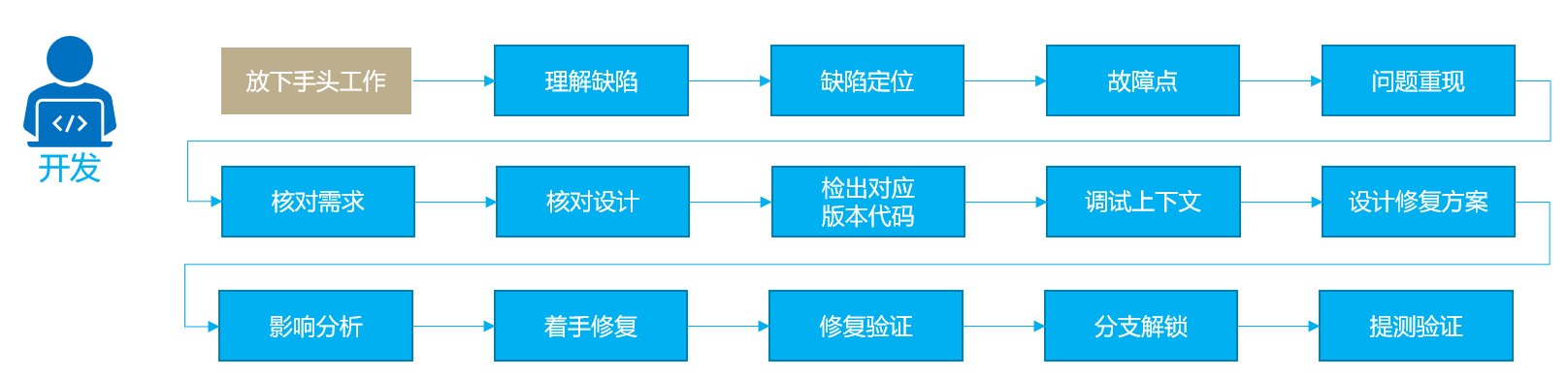
缺陷的定位可能是个复杂问题:金融科技等大型科技企业的应用系统起码上百个,仅仅确定缺陷归属是哪个系统,有时就需要多个应用系统出人“会诊”配合,才能完成初步的缺陷归属,再进入具体应用系统的修复过程。
缺陷重现有时候也比较困难,在测试环境内,有的数据“消耗”了,需要找合适的其他测试数据,甚至需要重“造”一份,也就是缺陷发生上下文和重现上下文不一致的问题。
生产环境的问题重现会更困难,开发人员还需要到生产环境去查日志和分析,需要遵守信息安全规范,通常耗时较多。生产故障往往是资深级开发人员出马,而资深开发人员的编码效率是最高的,用来返工是最高的“单位时间成本”。
由于安全规范和技术限制等原因,缺陷分析时,需要的远程调试能力往往也受限。
总的来说,返工流程的基本成本构成有:
◾ 开发人员和测试人员,以及与其他系统的开发测试人员的沟通协作成本;
◾ 信息获取成本:一是需要花时间重新理解上个版本代码,相关信息上下文。
某程序员的解释:编程是那种你必须同时在脑海中保留很多东西的任务。一次记住的东西越多,在编程方面的效率就越高。一个全速编码的程序员会同时在脑海中保留无数的东西:从变量的名称、数据结构、重要的 API、编写和调用的工具函数的名称,甚至是存储源代码的子目录的名称。如果你派他去克里特岛度假三周,他们会忘记这一切。人脑似乎将其从快速内存中移出,并将其交换到备份磁带上,磁带需要很长时间才能检索到需要的信息(注3)。
二是查找具体服务器或日志集中平台日志,相关具体测试数据等缺陷上下文信息;
◾ 一致性成本:让缺陷发生时的上下文、缺陷重现的上下文、缺陷修复再验证的上下文近一致性,典型如让缺陷复现的关联系统的版本、一致性(或等价)的测试数据,一些依赖组件及其版本、环境配置、应用配置等等。以完成缺陷可以定位、可以重现、可以分析和可以修复后验证;
◾ 任务切换成本:这是个容易被忽视的成本,并且付出的成本还不少。
开发人员需要放下手头工作(当前版本的代码开发),切换到处理(上个版本的)的缺陷。有开发经验的人都知道,编码过程需要整块的时间去思考,边思考边写代码,忌讳中途被打断,比如突然被拉去开会,开会回来后,之前思考的内容基本被清零,看着眼前写了一半的代码,心中一片迷茫,需要重新思考如何写,前面写的代码的思路是什么。假如原计划4个小时完成编码,由于中间1小时会议的插入,就可能需要额外增加1-2个小时完成原计划的内容;效率降低很大。
这与重新理解上个版本代码的原因有些类似,上个任务加载的信息都已经“从快速内存中移出…需要很长时间才能检索到需要的信息”。
会议我们可以有计划的开展,减少无端打断。但是生产故障来临时,是立刻,马上,刻不容缓的动起来去解决的。这就显著降低新版本的编码效率。
这种多任务切换导致的浪费在《Quality Software Management: Systems Thinking》(注4)这本书中有相关统计,双任务的切换成本会浪费20%工作时间,三个并发任务的切换成本会浪费一半以上工作时间。
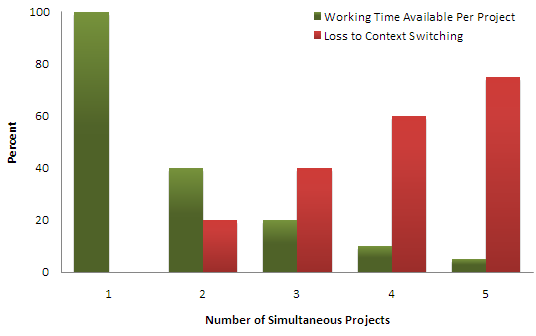
即使是短暂的“干扰”也会导致工作效率降低,根据BBC研究(注5),“被电子邮件和电话分散注意力的人的智商会下降10个百分点。大家也都听说过“封闭式开发”这种极限方法,用来排除一切外界干扰,以实现最高速率。当然这种方法副作用较大,不符合关注“倦怠”的DevOps文化。
◾ 生产故障特有的跨多部门、多人协作以及事后成本:生产故障还会有其他返工工作项,生产故障时是一个跨多部门,多人协作的处理流程,如下图,自右侧开始,生产上用户发现了一个缺陷,反馈给了支持人员,支持人员确认这是个缺陷后,转发给管理人员,这里的管理人员包括支持管理,开发管理,测试管理等。管理人员转发给开发人员和测试人员,开发人员修复后,测试人员对修复进行确认,再转发给管理人员评审,支持人员确认和补丁投产修复,最后由客户确认完成最终流程。
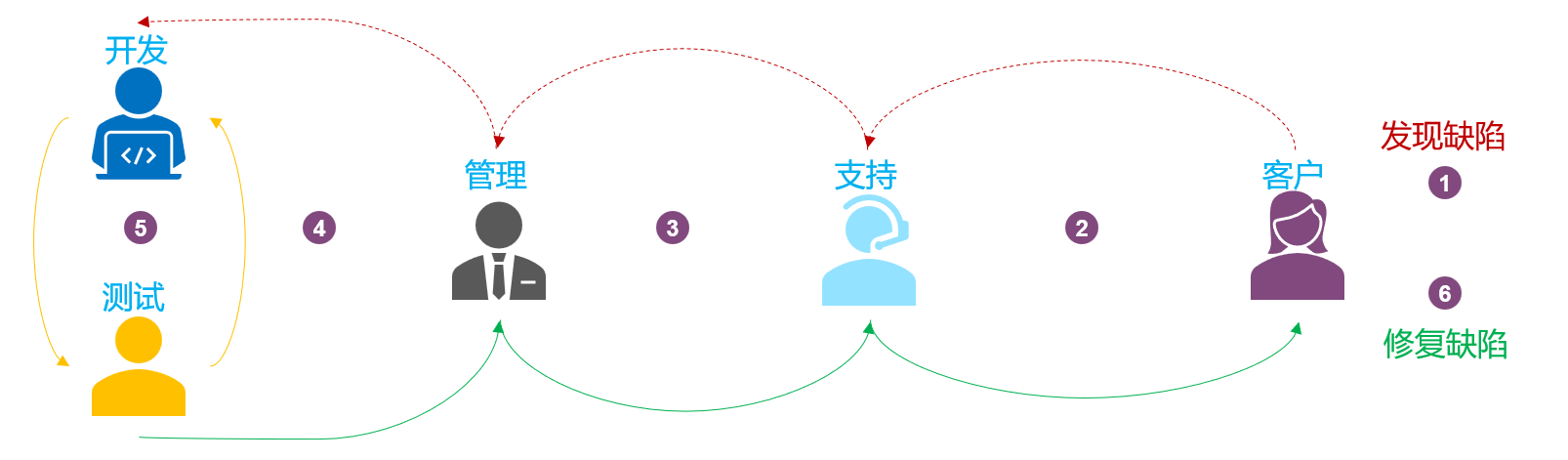
重大故障还会有更严格的根因分析和彻底解决举措方案的设计、评审、多级多次汇报、落地等一系列事后成本。
引用某大型股份制银行科技总经理的语录,“故障返工成本太高了,有时候甚至需要我周末赶到现场……”,“有的人天天忙着写新的bug,修复老的bug,要反思改变”, 顺便提下,正是由于该股份制银行从管理到研发都充分认知质量内建价值,三年内,该行活跃应用普遍采取质量内建实践,在提测SIT前,200+应用代码覆盖率达到了80+%,生产故障降低了3/4,研发效率提升了一倍。
2、尽早修复缺陷/故障的返工分析
与后期的返工对比,我们看看尽早修复的返工工作项。
质量内建的尽早修复,是在开发人员个人桌面电脑上,执行开发自测,在发现缺陷时,即时修复,再验证修复,有以下几个无(低)成本特征:
◾ 没有沟通和流程处理成本:开发自测,无需协作,solo(单人)完成;
◾ 没有信息获取成本:自测的是自己刚刚写的“热乎乎”代码,日志是IDE的输出,测试数据和环境都与编码环境一致,信息依旧还在“人脑内存”中;
◾ 没有任务切换成本:“热乎乎”代码的调试和自测的上下文复用,保持一致;不是别人的代码,也不是一个月前的代码;
◾ 没有一致性成本:自测发现的缺陷时的上下文和调试分析,以及修复后验证的上下文是复用的,所有内外部依赖,各种配置此时此刻都始终保持一致;
◾ 缺陷发现成本低:自己写的代码,无论是否自测,总需要编译跑起来看看,此时只是增加一些自测案例,让自测更规范,叠加成本很少。实践表明:在早期发现缺陷的 “发现成本”比后期“发现成本”低3-20倍(大家有兴趣可以统计下SIT测试人力,再除以缺陷数量 = 测试阶段的每缺陷发现成本)
写在最后
可以看到,质量内建下的尽早修复返工是自主控制、闲庭信步,后期修复返工是被动被催、营营碌碌。一个是低(无)成本预知,一个是处处有成本未知,后期修复成本高出100倍再正常不过了。
最后借用两段偈语表达下二者对待缺陷的“境界”:
🔹后期修复返工: 身是菩提树,心如明镜台,时时勤拂拭,勿使惹尘埃;
🔹尽早修复返工: 菩提本无树,明镜亦非台,本来无一物,何处惹尘埃;
注:
1. Boehm博士(软件工程界的巨匠,南加州大学教授,美国工程院院士,《软件工程经济学》经典著作的作者;
2. https://www.amazon.com/Applied-Software-Measurement-Analysis-Productivity/dp/0071502440
3. https://www.joelonsoftware.com/2001/02/12/human-task-switches-considered-harmful/?ref=blog.codinghorror.com
4. https://www.amazon.com/Quality-Software-Management-Systems-Thinking/dp/0932633722
5. http://news.bbc.co.uk/2/hi/uk_news/4471607.stm